面试刷题:经典算法思想之回溯法
By 青衣极客 Blue Geek In 2020-05-01
我们所遇到的算法问题五花八门,形态各异,但是从已有的那些解决方案中归纳出的经典算法思想却是屈指可数,而这些经典的前人经验基本涵盖了绝大多数计算机算法问题的解法。掌握这些经典的算法思想,对于解决程序设计问题而言,具有提纲挈领、纲举目张的效果。事实上,不仅仅对于算法问题,这些思想很大程度上也为解决现实世界的一些问题提供了思路。
回溯法就是这些经典算法思想之一,它实际上是一种通过枚举来搜索解空间的算法,主要思想是:在搜寻的过程中,如果当前这一步无法找到符合要求的解,则回退到上一步,然后继续搜索其他路径构成的解。 从逻辑结构上来说,回溯法也是一种深度优先搜索(DFS) 算法,因为常常需要搜索到叶子节点才能构成一个完整的解。在中间的任何步骤,一旦出现不合规的情况,就会“回溯”,则满足回溯条件的节点也称“回溯点”。
这里,我们以【Leetcode Q1415 长度为n的所有快乐字符串的第k个词典序的字符串】来讨论回溯法,并给出这种方法的通用模版。“回溯法”还有一个美名 —— “万能解法”。 也就是说,掌握了回溯法,记住了相关模版,对于绝大多数问题,至少能给出一种可行的解法,而不至于束手无策。
1. 题目 Q1415 第k个有快乐字符串
一个快乐的字符串 s 是一个string,它是由且仅由集合 [‘a’, ‘b’, ‘c’] 中的字母组成, 并且满足 除第一个字符以外的所有字符都不能与其前一个字符相同, 即 $s[i] != s[i - 1], i \in [1, n-1]$, 索引从 0 开始。
例如,字符串 “abc”,”ac”,”b “和 “abcbabcbcbcb “都是快乐的字符串, 而字符串 “aa”,”baa “和 “abababbc “不是快乐的字符串。
给定两个整数n和k,考虑一个词典序顺序排序的长度为n的所有快乐字符串的列表。 如果长度为n的快乐字符串少于k,返回一个空字符串;否则返回该列表中的第k个字符串。
说得简单一点,也就是对于长度为n的所有满足条件的“快乐字符串”按照词典序进行排序,然后取第k个作为返回值;如果第k个不存在,就返回空字符串。
约束条件:
(a) 1 <= n <= 10
(b) 1 <= k <= 100
示例
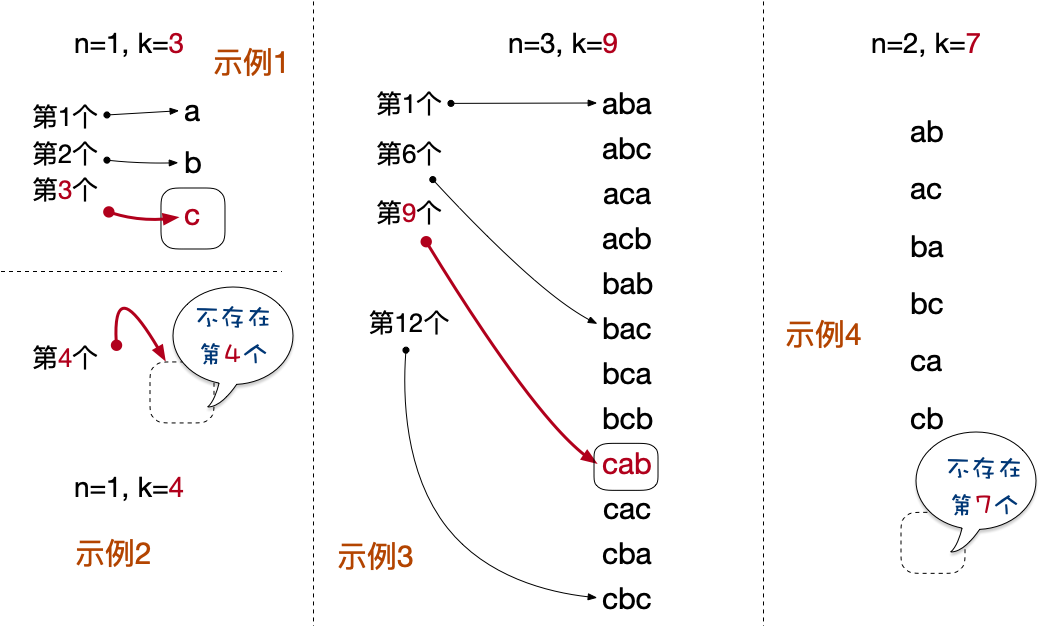
四个输入输出的示例如图所示:
2. 回溯法
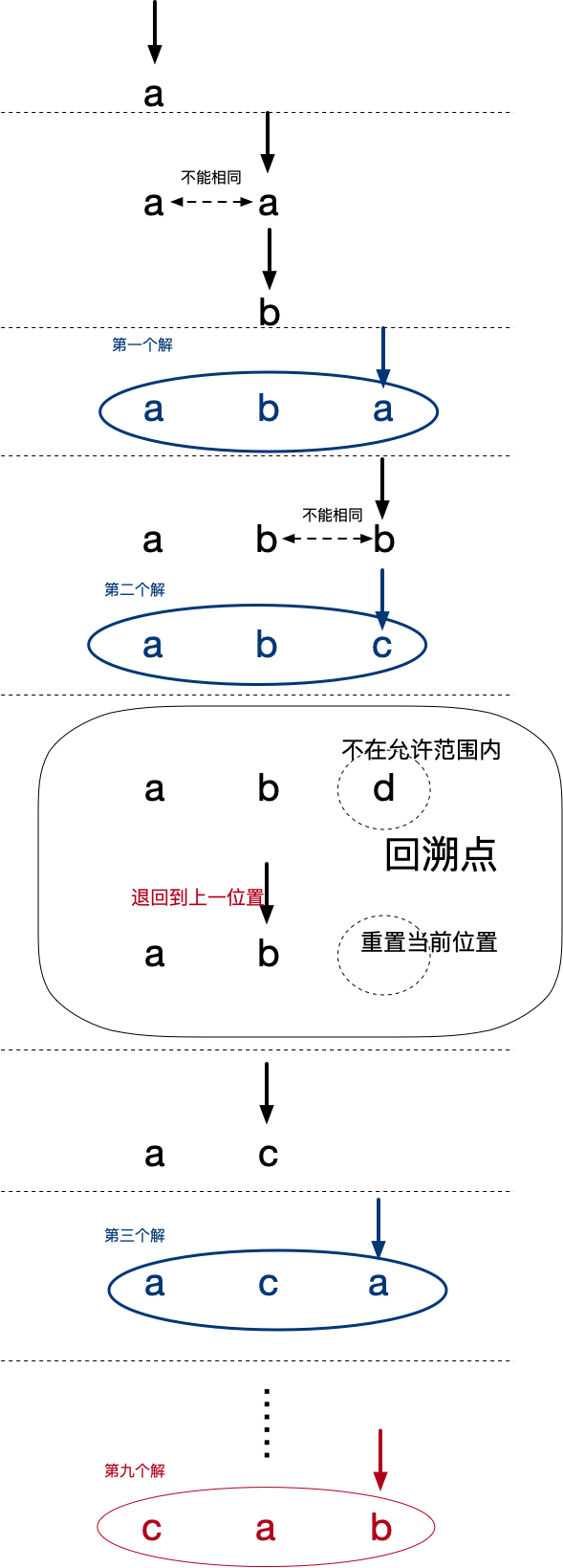
根据题意,可以想出一种很直观的解决思路:逐个枚举符合要求的字符串,一直到第k个就是我们想要的最优解。 要枚举字符串,就需要确定字符串的每一位字符,而且要求按照字典序枚举。每一位字符必须是 [‘a’, ‘b’, ‘c’] 中的任意一个,并且相邻字符不相同,这就构成了约束条件。如果设置的一位字符不满足约束条件,那就需要退回到上一位字符,接着枚举。每到最后一位设置完成,则构成一个解;一直数到第k个。这就是“回溯法”的基本思路。 更加形象的描述如图所示:
对于回溯法这样一个形式化的解决思路,是有固定模版的。也就是说,在运用回溯法时,我们只需要按照模版填写进相应的部分即可。目前常用的模版有两种:递归模版和while模版。
(1). 递归模版
使用递归来实现回溯法是比较简洁的,在面试或者时间要求紧迫的情况下推荐使用递归模版。
void _dfs(各类资源, int pos) {
if (满足最优解终止条件) {return;}
if (找到一个解的终止条件) {
if (是最优解) {记录最优解}
return;
}
for (遍历当前节点的所有可能解) {
if (判断约束条件) {
// 设置当前位置
// 搜索下一个位置
_dfs(各类资源, pos+1);
// 清理工作
}
}
}
这个模版还是非常简单的,建议最好记住,这样在使用时能够很快写出。
关于Q1415这个问题的使用递归模版的C++解决方案如下:
// Runtime: 0 ms, faster than 100.00%
// Memory Usage: 5.9 MB, less than 100.00%
class Solution {
private:
void _dfs(string & slt, string & k_slt, int & k, int pos) {
// 最优解终止条件
if (0 == k) {return;}
// 找到一个解的终止条件
if (slt.size() == pos) {
if (0 == (--k)) {k_slt = slt;}
return;
}
// 遍历当前节点的所有可能解
for (char ch = 'a'; ch <= 'c'; ++ch) {
// 判断约束条件
if (0 == pos || slt[pos-1] != ch) {
// 设置当前位置
slt[pos] = ch;
// 搜索下一个位置
_dfs(slt, k_slt, k, pos+1);
}
}
}
public:
string getHappyString(int n, int k) {
string slt(n, 0), k_slt;
_dfs(slt, k_slt, k, 0);
//cout << slt << "," << k_slt << "," << k << endl;
if (0 == k) {return k_slt;}
return "";
}
};
使用递归来实现,代码形式确实非常简单,但是会有一个问题:每次函数调用都需要压堆栈,如果解空间的长度很大,那么递归深度过深可能导致堆栈溢出。在Q1415这个问题中没有表现出来是因为,测试用例中的字符串长度都不超过100。但是在自己日常开发中有可能没有这么幸运。
(2). while模版
由于递归方法对于深度存在一定的敏感性,因此while模版实现的方法有了一定的意义。以下就是while模版:
while (设置索引位置的条件限制) {
if (搜索到一个解) {
if (搜索到符合条件的最优解) {
结束搜索
break;
} else { // 不是最优解,则开始回溯
返回上一个位置
}
} else {
设置当前位置第一个可能的解
while (不满足约束条件) {
尝试下一个
}
if (判断当前解符合要求则尝试下一个) {
标示当前位置
开始下一个
}
// 判断当前解不符合要求,则回溯
else {
清理当前状态
返回上一个位置
}
}
}
从以上代码可知,while模版使用起来确实没有递归模版简洁,但是却可以避免频繁地压堆栈。使用while模版实现Q1415的C++解决方案如下:
// Runtime: 0 ms, faster than 100.00%
// Memory Usage: 6.1 MB, less than 100.00%
class Solution {
public:
string getHappyString(int n, int k) {
// 初始化字符串
string slt(n, 0); // 状态存储器
string k_slt; // 最优解记录器
int pos = 0; // 搜索索引位置
// 设置索引位置的条件限制
while (pos >= 0 && pos <= n) {
//cout << pos << "," << slt << "," << k << endl;
if (pos == n) { // 搜索到一个解
// 搜索到符合条件的最优解,结束搜索
if (0 == (--k)) {
k_slt = slt;
break;
} else { // 不是最优解,则开始回溯
// 回退索引
--pos;
}
} else {
// 设置slt[pos]的第一个可能字符
if (slt[pos] == 0) {
slt[pos] = 'a';
} else {
++slt[pos];
}
// 搜索slt[pos]
while (pos > 0 && slt[pos-1] == slt[pos]) {
++slt[pos];
}
// 判断当前解符合要求则尝试下一个
if (slt[pos] >= 'a' && slt[pos] <= 'c') {
// 标示当前位置,上面已经完成
// 开始下一个
++pos;
}
// 判断当前解不符合要求,则回溯
else {
// 清理当前状态
slt[pos] = 0;
// 返回上一个
--pos;
}
}
}
if (0 == k) {return k_slt;}
return "";
}
};
从评测数据来看,两种实现似乎没有太大差别,这主要是由于测试用例的覆盖面不够广。不过在实际使用时,也有很多场景本身的可能性非常有限,这时,使用递归模版实现仍然是一种非常不错的选择。
关于回溯法的时间复杂度是 $2^n$,但是在这个问题中的时间复杂度可以简化一些, 即O(n + k),需要注意的是k的最大值与n存在关系,这里直接使用 k 来简化描述。
3. 数学方法
回溯法可能是万能解法,但常常并不是最好的解法。 我们当然很有必要掌握回溯法,毕竟能给出解决方案与不能给出解决方案之间的差别很可能让你通过或者通不过面试。但是对于有些问题,如果我们仔细分析其特点,如果能够利用数学规律,有可能会设计出更加高效的算法。对于Q1415就有对应的数学解法。
我们重新来思考这个问题,“能不能快速地判断第k个字符串是否存在?” 是否必须逐个枚举才能确定第k个是否存在呢?不是,我们可以通过数学计算获知这一点,至于怎样获知,下文将揭晓。
对于一个长度为 n 的字符串,每个字符只能在三个字符中选一个,那么理论上每一位字符都有三种可能。但是还有个条件未使用,“相邻字符不能相同”。也就是说,在前一个字符确定的情况下,当前字符只有两种可能。 而第一个字符由于没有前一个字符,因此它有三种可能。这样想清楚就会发现,长度为 n 的字符串有 $32^{(n-1)}$ 种可能性。* 通过比较 k 与 $3*2^{(n-1)}$ 的大小可以“快速地判断第k个字符串是否存在”。
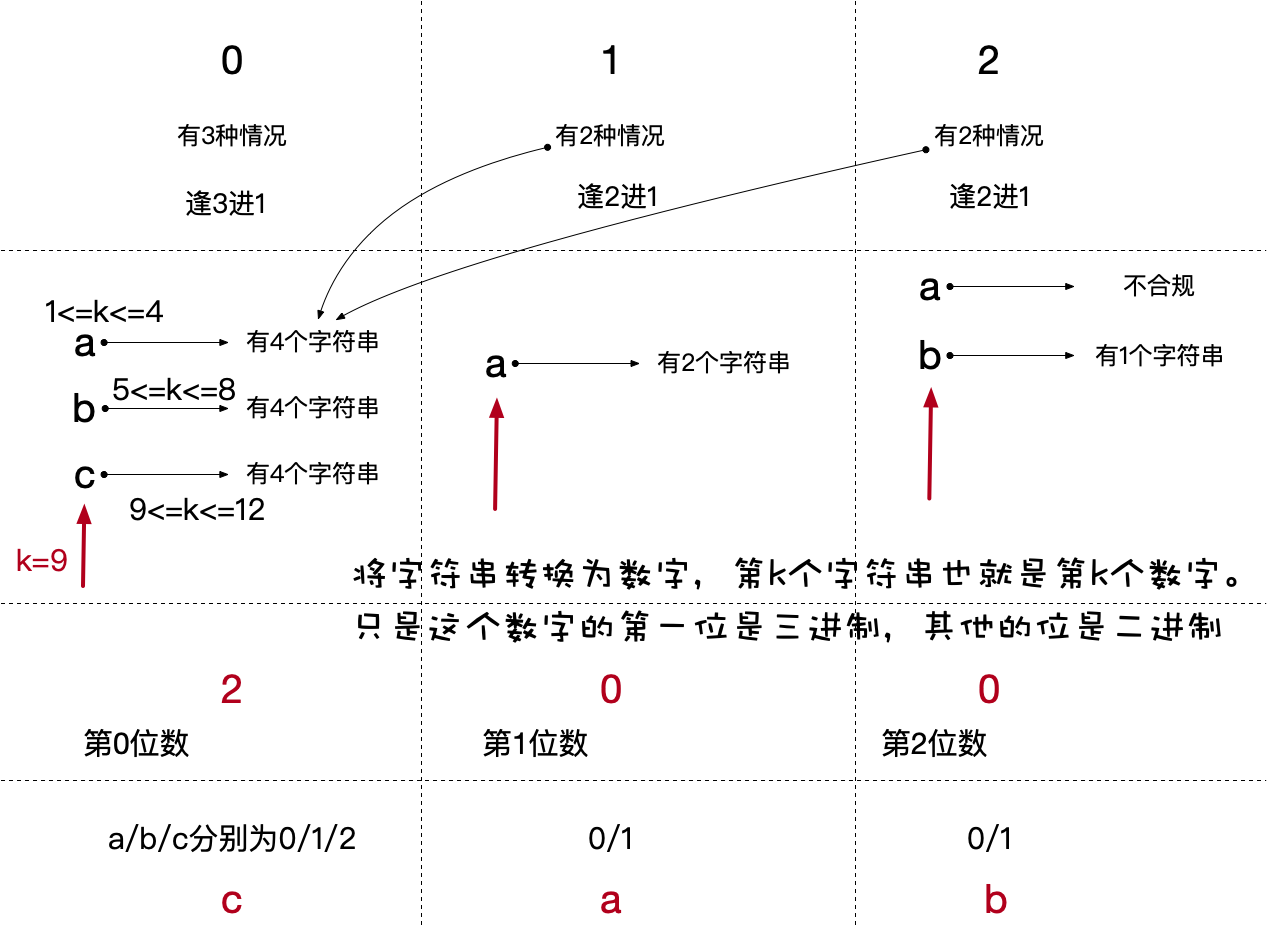
对于这一点的利用,还不仅仅在于解决这个小问题。我们再来思考这个问题,如果我们将这个字符串看作一个数字,确定字符串的每一位就是确定这个数字的每一位。 根据上面的分析可知,这个数字的第一位是3进制,其他位是二进制的。 如果我们能够确定下来第k个特殊的数字,那么就可以逐个确定下来每一位字符。采用这种“特殊数字”的数学方法的操作说明和示意图如下:
有了这种思路之后,实现起来就好说了,这里直接给出C++的解决方案。
// Runtime: 0 ms, faster than 100.00%
// Memory Usage: 5.9 MB, less than 100.00%
class Solution {
public:
string getHappyString(int n, int k) {
// 第一个字母有3种选择,其他字母都只有两种选择。
// 总的情况个数为3*2^(n-1)
int t = 3;
for (int i = 1; i < n; ++i) {
t <<= 1;
}
if (k > t) {return "";}
// create each char in the answer string
string letters = "abc", ret;
int count = 0, idx = 0;
for (int i = 0; i < n; ++i) {
if (0 == i) { // for the first char
t /= 3;
} else { // for the others
t >>= 1;
}
// count bits
for (count = 0; k > t; ++count) {k -= t;};
// find index
for (idx = 0; (ret != "" && ret.back() == letters[idx]) || (count--); ++idx);
ret.push_back(letters[idx]);
}
return ret;
}
};
数学方法的时间复杂度也很明确,即 O(n + log(k))。也就是说,即使 k » n,对运行时性能的影响也不会太大。
从Leetcode网站评测来看,这三种方案的性能差不多,但是复杂度分析表明:数学算法的时间复杂度在极端情况下会显著优于回溯法。字符串的长度 n=100 时,k最大可能取 $32^{99}$。也就是说在这种极端情况下,回溯法很可能在可预期的时间内无法计算完成;而数学方法对于k » n 这种极端情况与 k==1 这种简单情况的运行开销区别并不大。*
最后,还需要说的一点是:数学方法不常有,还是回溯法更保险。 掌握这些经典的算法思想比灵光乍现的数学方法要重要得多,毕竟灵感不常有,而题确是源源不断的。

COMMENT
博客评论区功能由Github Issue提供,提交Issue时请以本文标题为话题。
"BG97-面试刷题:经典算法思想之回溯法 Q1415"